The Dem-Ist database offers access to the information contained in forms type A under the form of data sets, of digital transcriptions compiled as population samples. We hope that in the future we will be able to also incorporate images in the site. Until then we will explain how the process of compiling these samples takes place.

We based our work on the following principles:
• Source integrity: we intend to publish the source in its entirety;
• Precision in regard to the source’s tabular form: we intend to replicate as much as possible the form’s table (columns);
• Scientific compatibility. Like in any other approaches to edit historical sources, we were guided by the intention not just to ease access to the information, but also to make this information easier to use, regardless of the scientific field.
We can further add general rules that apply to any database:
• Uniformity of the types of entries. Along the whole dataset, each row has to represent the same type of item. In our case, 1 row = 1 person.
• Parity between variable and types of information, meaning that 1 column (variable) = 1 type of information.
We did our best to follow all the above principles, but in many instances the source presented contradictions between them, so compromises had to be made.
First, we had to separate the main body of the form – the table – from the aggregates recorded at the end of each settlement: the sums of persons and different items. These were extracted in different files and published as such.
Within the tables we had to divide the columns that included more than one aspect. For the optimal use of the resulting digital table, it is necessary that each aspect is individualized in unique columns. At the same time, this intervention does not alter the meaning of the historical information, it is just a means of conveying coherence in a digital and scientific setting.
Transcription
In this phase we inputted the text from the source in a digital spreadsheet, by transcribing the Romanian Cyrillic writing of the age into present day writing.
It was also at this moment that we separated the census forms from the census aggregates.

In addition, we divided certain original columns into multiple digital columns (variables), as said earlier and exemplified below.
Harmonization, or standardization, coding
In this phase, work consisted of supplementing the original content with one that is standardized and can be used in scientific analysis. This does not imply replacing the columns from the historical form, or altering the content of the basic transcription; but generating new columns, in which the previous content is given a coherent form. For example, instead of resorting to use several terms that represent filiation – băiat (boy), băieţi (boys), fii-său (his/her son), fiu-său (his/her son), fecioru său (his/her son/lad), fii-sa (his/her daughter), fata sa (his/her daughter), fete (girls), fată (girl) – we should more effectively use only one: child, with the sex coded in a separate variable.
Generally, this phase meant:
• Creating variables where the historical content does not come in serial form (it is not structured as a column in the table). These variables refer to geographic and administrative information, or the person’s sex (which was inferred);
• Standardizing variables already present, that resulted from the basic transcription;
• Creating additional variables, where standardization of the latter is not enough to make the information processable in a proper analysis. Such variables refer to:
• Overall, using a language (labels) compatible in the wider field of historical demography or digital humanities – meaning using standardized models of coding.
The models used by Dem-Ist so far are:
• The concept of Conjugal Family Unit (CFU), used in the broader field of family demography for coding the relation inside the nuclear family; (see below);
• the coding systems for household status, age, sex and marital status used by the MOSAIC project (https://censusmosaic.demog.), in turn inspired from the North Atlantic Population Project and IPUMS (https://www.nappdata.org/);
• the HISCO coding system for occupations HISCO (Historical International Standard of Classification of Occupations - https://collab.iisg.nl/web/).
Exemplification
The entire process of digitization was more thoroughly documented in two publications available on this site (see Publications).
Next, we will provide brief visual examples of the manner in which the source was edited. We will take each chapter of information and present the way it looks in the source, in the basic transcription and in the harmonized version.
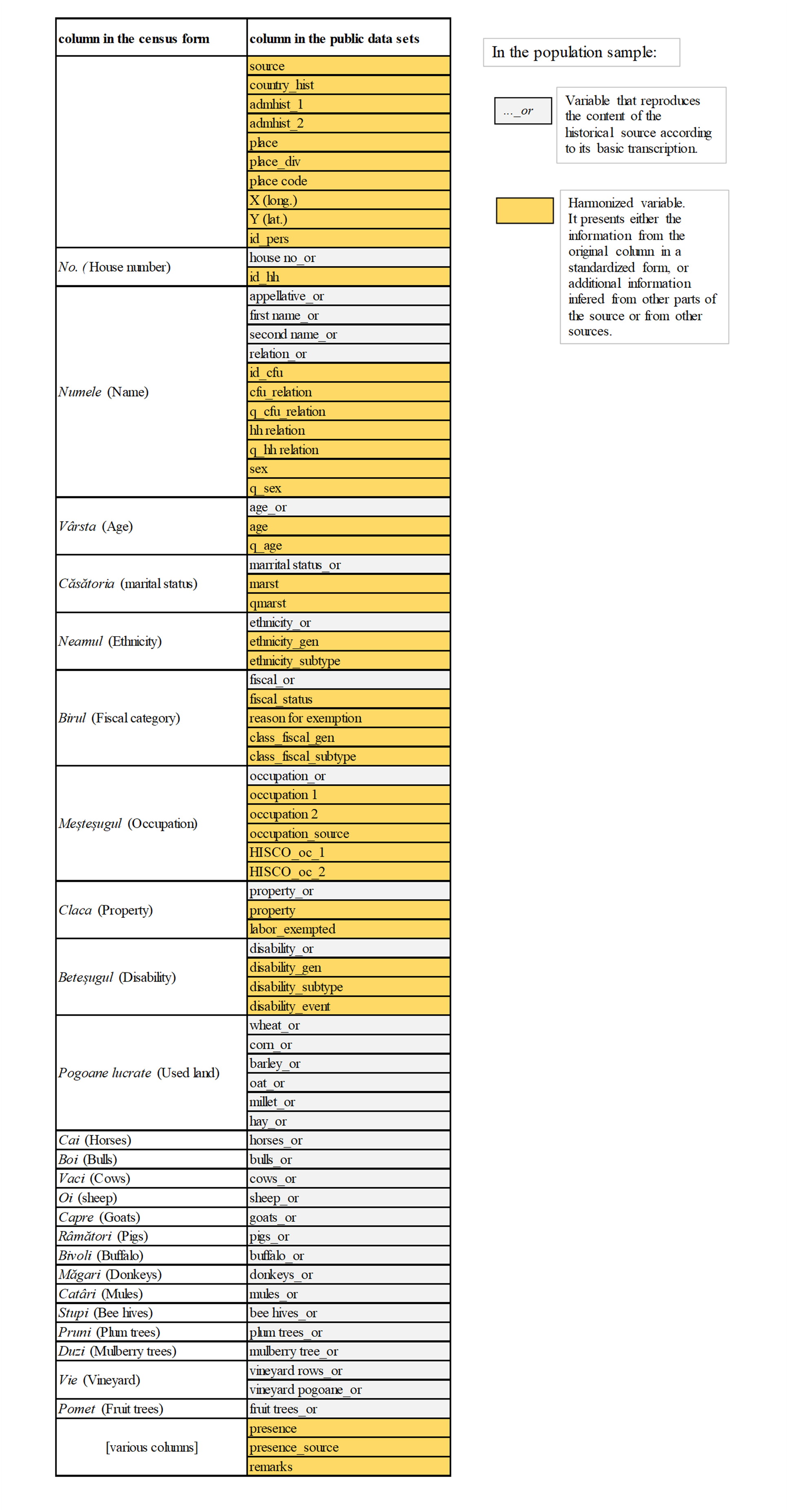
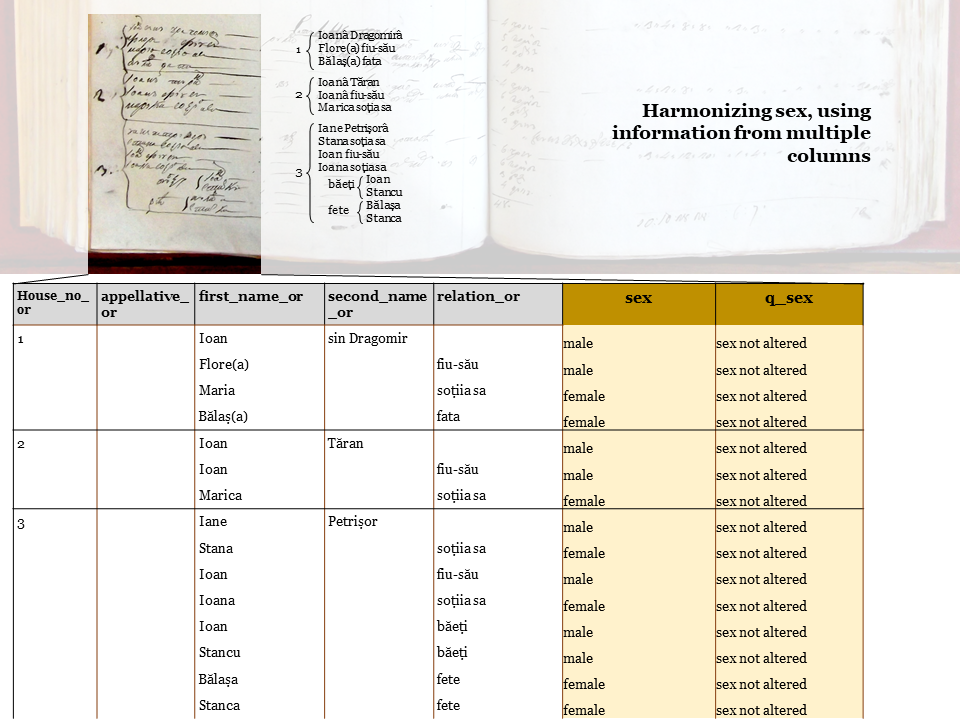
Below, in white, we represented the part of the source that is present in the dataset (population sample) as it was transcribed. The respective variables received _or in the ending of their title, meaning ”original”.
In orange we depicted the harmonized content of the dataset.
Our examples refer to the first three houses from village Negoiu, subdistrict Balta, district Dolj.

First, we had to mark all entries according to basic descriptors and locators: name and year of the source, historical country, historical administrative units, historical divisions of the settlement. We deemed it necessary to also generate a code for each place (settlement) and to give the geographic coordinates of each place, in decimal format.
Each individual also received a unique code.


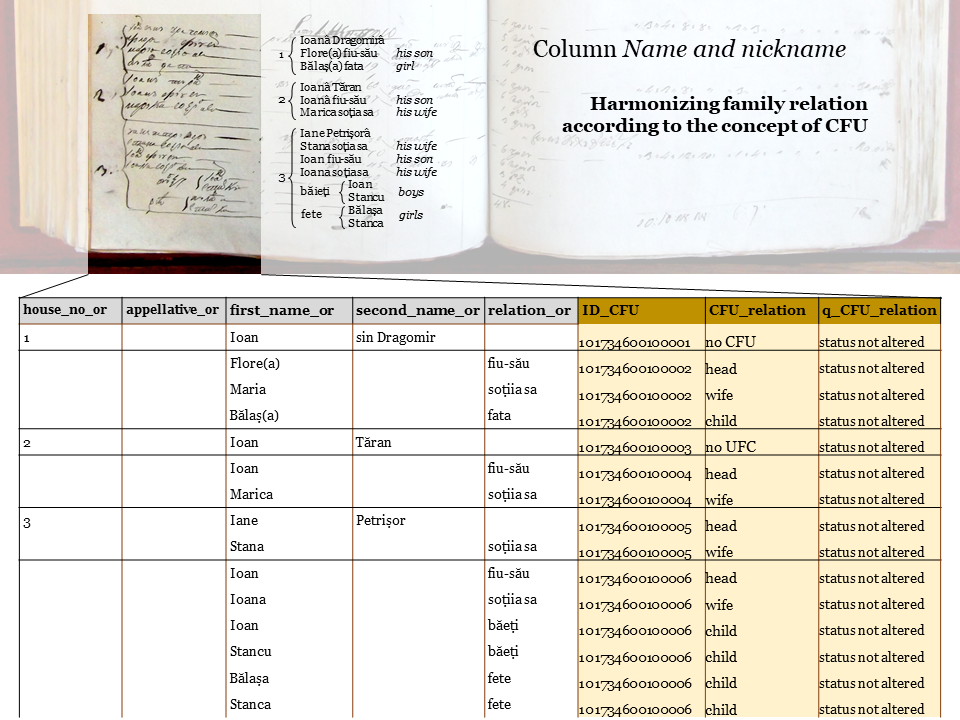
The column Name was divided artificially into four columns: appellative (for cases where appellatives were written down before the actual name), first name, second name and relation. The latter refers to one’s status both inside the family and the household.
Next, we harmonized the information for the nuclear family, according to the concept of Conjugal family unit (CFU). 1 CFU = 1 married couple with/without never married children, or a lone parent with never married children. Each CFU received a unique numerical code in a separate variable.
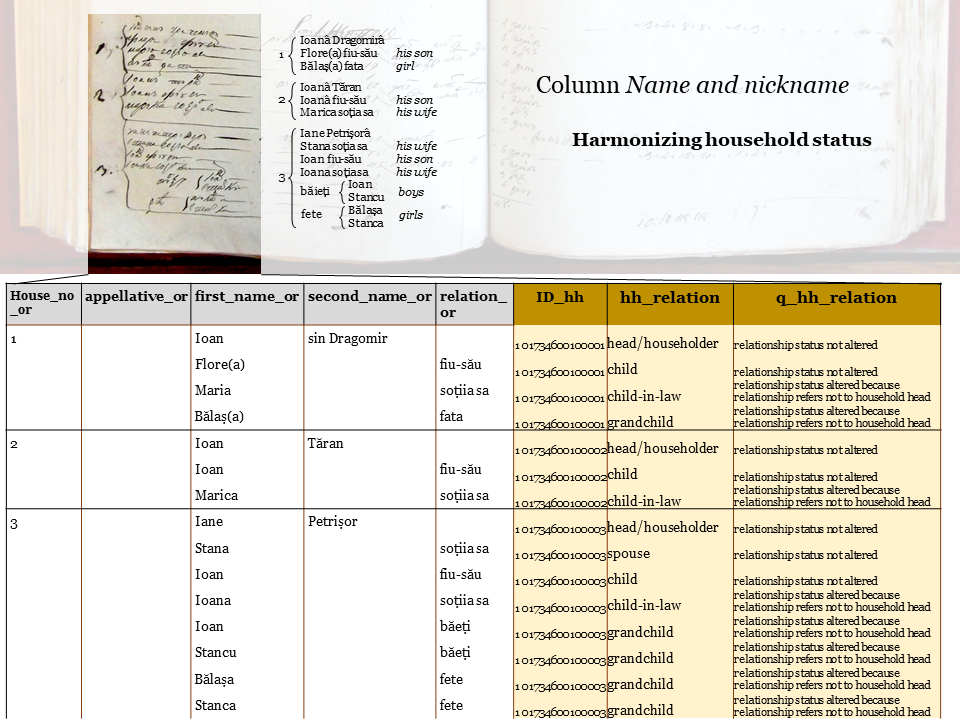
We proceeded to do the same with household status. In this context, the household is understood to represent all those grouped under the same house number. The status of each person was coded by relating it to the head of the household (the householder = the first person listed under a certain house number), following the example of MOSAIC and NAPP.
The sex was harmonized as follows.
Ethnicity is represented in the publicly available datasets as one original variable and two harmonized variables (no international standards were used).

Marital status: original column + two harmonized variables, following the practices of MOSAIC and NAPP.

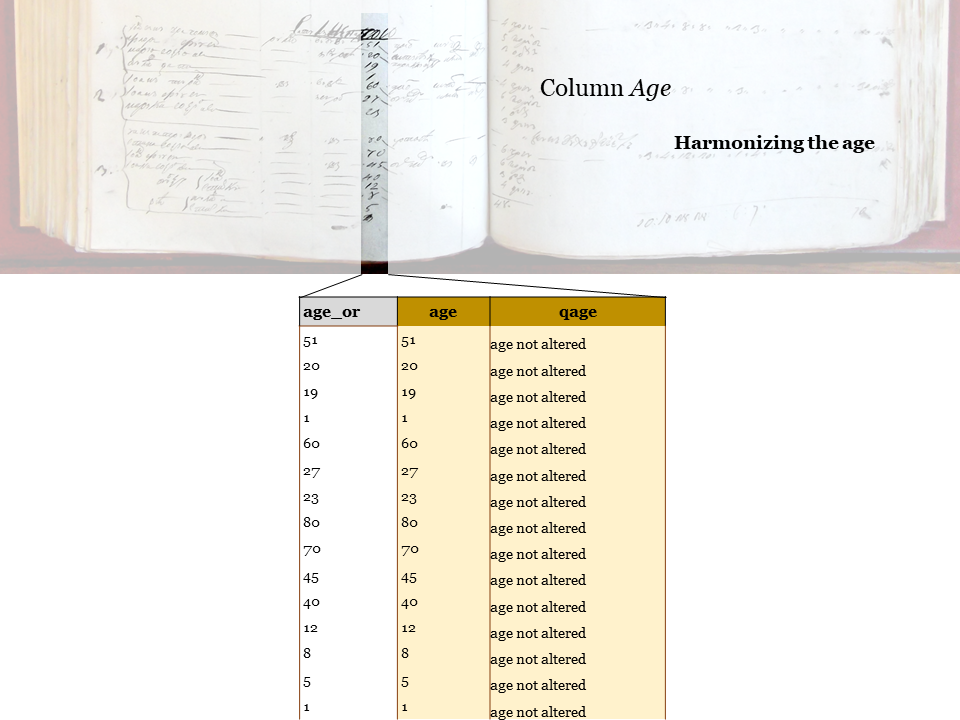
Age: the original column + two harmonized variables, following MOSAIC and NAPP.
Fiscal category was problematic because it overlapped with occupation and social category. We reproduced the original column, and had to harmonize not only the fiscal information, but also that regarding social category, ONLY IF the latter could be inferred from this particular column.

Property status was processed as follows (no international standards were used):

In the census we have a column reserved for occupation, but similar information can also be found in the column Fiscal category, depending on the recorded person or the census taker. Example: if some persons were exempted from taxation because they were priests, some officers specified their occupation under Fiscal category, without repeating the mention under Occupation. Other census takers wrote down ”priest” under Occupation and marked the person as ”exempted” under Fiscal category.
We transcribed the column Occupation as it appears in the original forms, giving it the title occupation_or. Separately, we harmonized the information available for occupation by using the content from both columns, if necessary. A special variable indicates the source of the information.
In addition, we created two harmonized variables, to cover cases where a second occupation was recorded.
Lastly, we coded the occupation by HISCO codes.

Used land is present in the population sample in the form of the basic transcription.

Information regarding disabilities is present in one original column and two harmonized variables.

Information on other agricultural resources is also present as they were transcribed.

Finally, we included a column titled ”remarks”, where we marked unusual situations such as uncertain readings of the historical writing, or irregularities that were not distinguished in the quality-flag variables.
Symbols used in the basic transcription are:
• „!!” – for cases where the census taker left the space empty. We marked unused space in two major instances:
• „(...)” – for cases where we could not decipher (one or several words).
Below, a complete image of the variables contained in the public samples, and the relation between them and the historical census form.